El modelo Decision Field Theory de Busemeyer (1992, 1993) surge como a una alternativa a los modelos de decisión clásicos en el estudio de toma de decisión bajo riesgo e incertidumbre. Su objetivo es modelar el proceso de deliberación que lleva a la toma de decisiones, en lugar de simplemente describir el resultado de la decisión. Para ello se busca modelar dos fenómenos ampliamente documentados en la literatura de toma de decisiones.
Inconsistencia en las preferencias.
El tiempo disponible para decidir afecta la elección.
El primer punto se refiere a que la transitividad entre las preferencias no siempre se cumple, es decir, si una persona prefiere A a B y B a C, no necesariamente preferirá A a C. El segundo punto da cuenta que la probabilidad de elección entre varía conforme pasa el tiempo, dado que se va acumulando evidencia a favor de una opción causando que con menor cantidad de tiempo se elija una alternativa que podría no ser la preferida con mayor tiempo de deliberación.
Construcción del Modelo
Para constuir el modelo Busemyer en su artículo Decision field theory: A dynamic-cognitive approach to decision making in an uncertain environment (1993) da una serie de bloques que se añaden para crear el modelo basandose en modelos previos de toma de decisiones. En esta sección se resumira la construcción del modelo.
Figura 1: Construcción del modelo Decision Field Theory. Obtenida de Busemeyer y Townsend (1993).
Modelos de Utilidad Esperada Subjetiva
Utilidad Esperada Subjetiva (SEU).
Las primeras tres etapas se basan en un modelo de utilidad esperada subjetiva (SEU, por sus siglas en inglés) que se utiliza para calcular la utilidad de cada opción. La utilidad se calcula al ponderar el valor de cada acción o decisión por la probabilidad subjetiva de que ocurra, este factor de ponderación igualmente se puede interpretar como la cantidad de atención que se le da a cada opción.
Para ejemplificar el modelo se supondrá que se tienen dos opciones las cuales pueden conllevar a dos resultados diferentes cada uno con cierta probabilidad y cada posible resultado tendrá un valor. Se denotará las distintas acciones como A y B, sus posibles resultados como subíndices 1 y 2, y las probabilidades subjetivas de que ocurran como \(w(S_1)\) y \(w(S_2)\), respectivamente. La utilidad de cada resultado se denotará como \(u(A_1)\), \(u(A_2)\), \(u(B_1)\) y \(u(B_2)\). Entonces el utilidad esperada subjetiva (\(v\)) de cada elección se puede expresar como:
La elección entre las dos opciones se basa en la diferencia de utilidad entre las dos opciones, es decir, la opción con mayor utilidad esperada subjetiva será la elegida, matemáticamente esto se expresa como una diferencia de utilidad:
\[
d = v_A - v_B
\]
Y la regla para decidir es:
\[\begin{equation}
Decisión =
\begin{cases}
A & \text{si } d > 0\\
B & \text{si } d < 0\\
\text{Indiferencia} & \text{si } d = 0
\end{cases}
\end{equation}\]
Utilidad Esperada Subjetiva Aleatoria (RSEU).
El modelo SEU supone que la atención a cada opción es igual para cada presentación del mismo par de opciones. El modelo RSEU relaja esta suposición y permite que la atención a cada opción varíe en cada presentación, la diferencia \(d\) en cada ensayo es aleatoria y es llamada valencia diferencial (valence difference). En este modelo el peso atencional \(W(S_i)\) es una variable aleatoria que varía de ensayo a ensayo, representando así la flutuación en la atención.
Como consecuencia la utilidad de cada opción se convierte en una variable aleatoria que a partir de ahora se le llamará como valencia (\(V\)). La cual se cálcula de firma idéntica al modelo SEU. La diferencia entre las valencias ahora se nombra como estado de preferencia\(P\), para cada ensayo y se cálcula como:
\[
P = V_A - V_B = d + \epsilon
\]
Donde \(\epsilon\) es un término de ruido que sigue una distribución de probabilidad, este término es el que permite que la elección varíe en cada ensayo. Por tanto, la probabilidad de elegir A sobre B se puede expresar como:
\[
Pr(A, B) = Pr(P > 0) = Pr(\epsilon > -d)
\]
En muchos modelos de este estilo se supone que \(\epsilon\) sigue una distribución normal con media 0 y varianza \(\sigma^2\). Por tanto, la probabilidad de elección se puede expresar como:
\[
Pr(A, B) = Pr(\epsilon > -d) = \Phi\left(\frac{d}{\sigma}\right)
\]
Donde \(\Phi\) es la función de distribución acumulada de la distribución normal estándar. La cuál se puede visualizar en la siguiente gráfica para distintos valores de \(\sigma\) y \(d\).
Código
import numpy as npimport scipy.stats as statsimport plotly.express as pximport plotly.io as pioimport pandas as pdpio.renderers.default ="iframe"sigmas = [0.1, 0.5, 1, 2, 5]x = np.linspace(-5, 5, 1000)y = [stats.norm.cdf(x/sigma, 0, 1) for sigma in sigmas]dic_y_data = {f"{sigma}": y_data for sigma, y_data inzip(sigmas, y)}df = pd.DataFrame(dic_y_data)df["d"] = xfig = px.line(df, x="d", y=df.columns[:-1], title="", labels={"variable": "σ", "value": "Pr(A, B)"})fig.update_layout( xaxis_title="d", yaxis_title="Pr(A, B)", legend_title="σ")fig.show()
Como se observa la probabilidad ahora depende de la diferencia entre las valencias y la varianza de la distribución de ruido. A mayor varianza la probabilidad de elección se vuelve más aleatoria, mientras que a menor varianza la elección se vuelve más determinista. Este parámetro se toma en cuenta para modelar la variabilidad en la elección y es llamado varianza de la valencia diferencial.
Utilidad Esperada Subjetiva Secuencial.
El modelo SEU y RSEU suponen que la elección se realiza en un solo paso donde se calcula la utilidad de cada opción y se decide. Sin embargo, en la vida real esto no sucede dado que se toma tiempo en evaluar las opciones y se acumula evidencia a favor de una opción. Para modelar este proceso se añade una etapa de acumulación de evidencia a favor de una opción y se decide cuando la evidencia acumulada supera un umbral.
Arreglemos las ecuaciones de arriba para tomar en cuenta la acumulación de evidencia. En primer ligar nuestro estado preferencial ya no es estático sino que varía en el tiempo, por tanto se puede expresar como:
Y nuestra regla de decisi es: \[\begin{equation}
Decisión =
\begin{cases}
A & \text{si } P(n) > \theta\\
B & \text{si } P(n) < -\theta\\
\end{cases}
\end{equation}\]
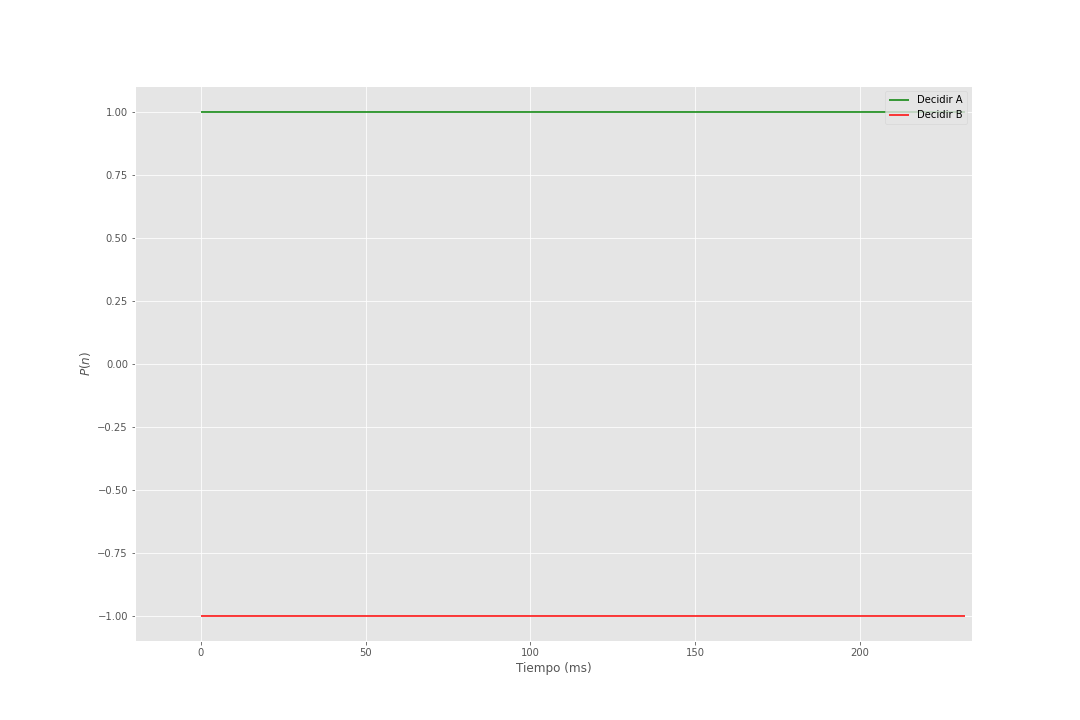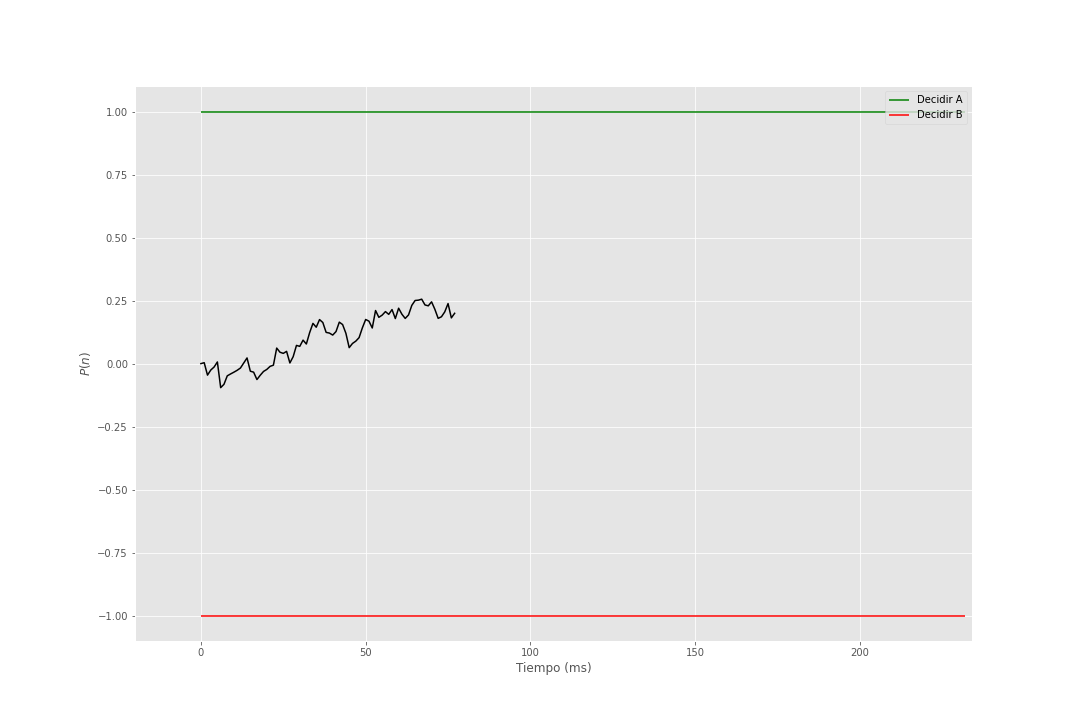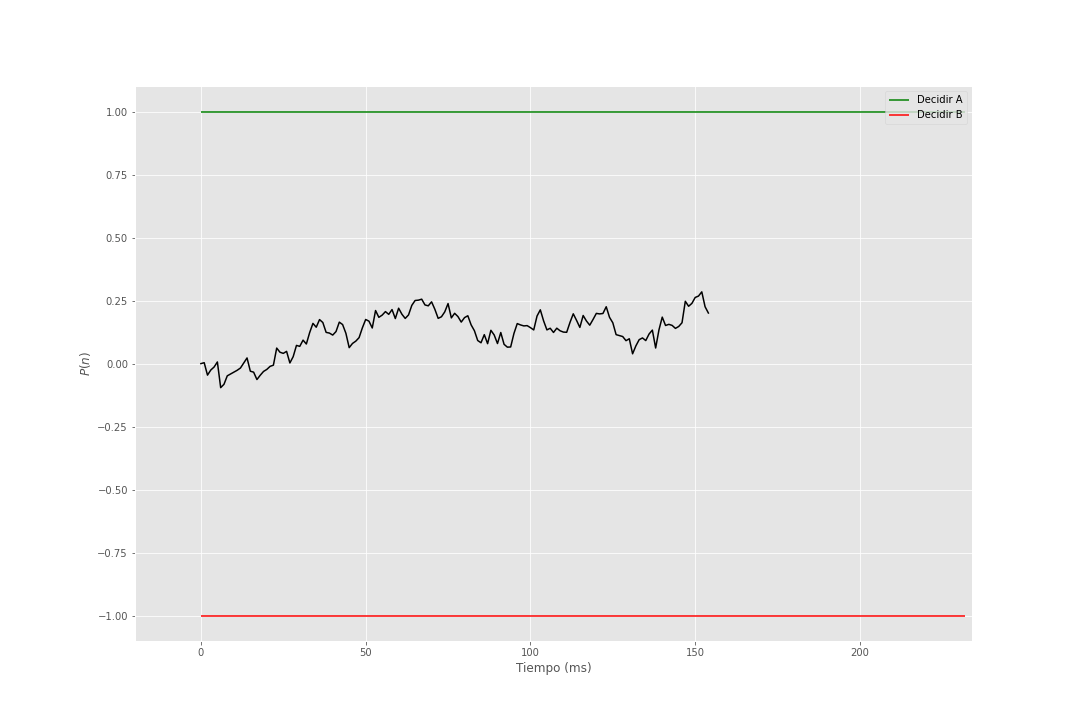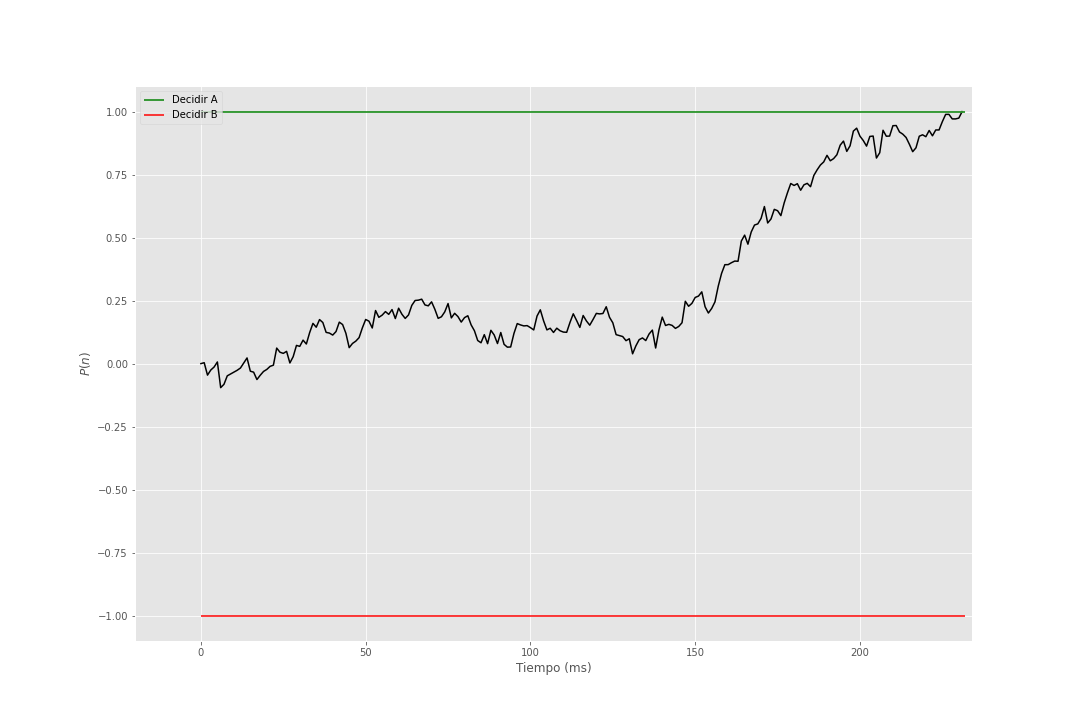
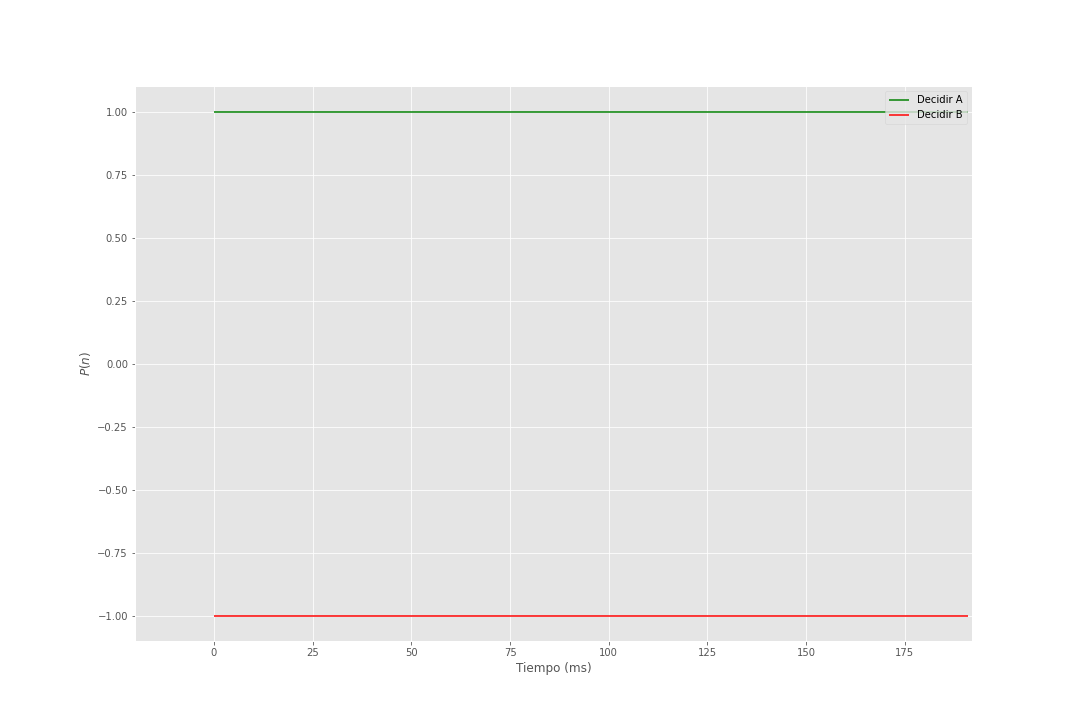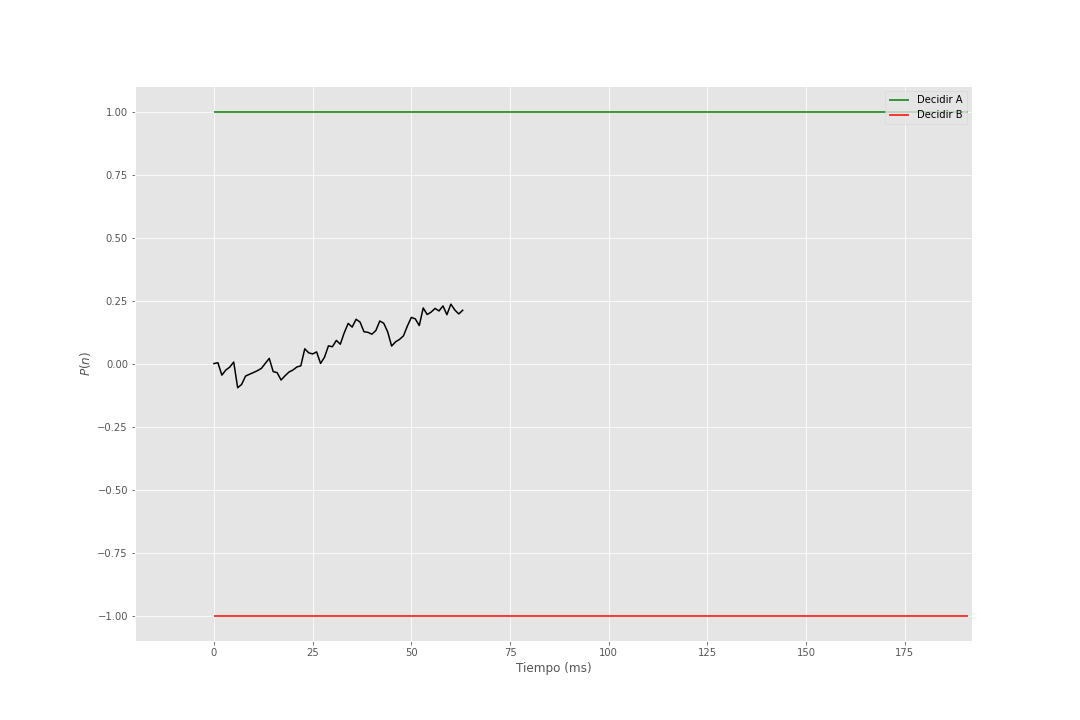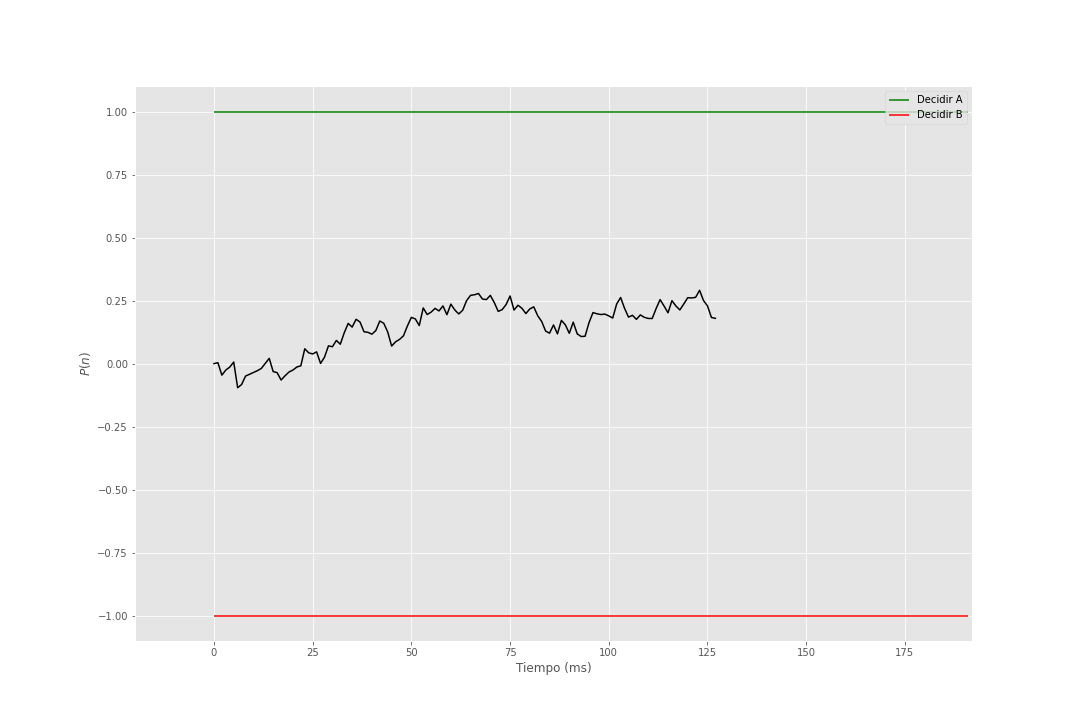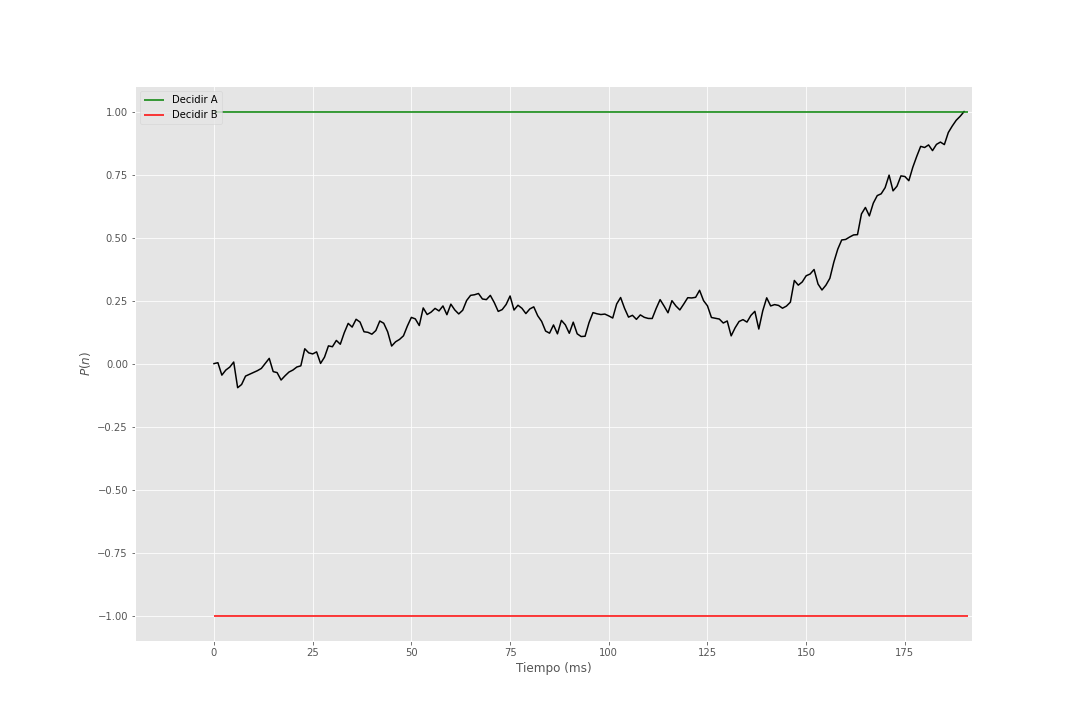
En el siguiente gif se muestra la acumulación de evidencia para distintos valores de \(\theta = 1\) y \(\sigma = 1\).
Figura 2: Modelo de Utilidad Esperada Subjetiva Secuencial
Se puede obtener la distribuvión de probabilidad de elejir A antes que B dado los valores de los parámetros \(\theta\), \(\sigma\) y \(d\), la cual se puede expresar como: \[
Pr(A, B) = Pr(P(n) > \theta) = F \left( 2 \cdot \frac{d}{\sigma} \cdot \frac{\theta}{\sigma} \right)
\]
En este caso \(F\) representa la distribución logística acumulada. En las siguientes gráficas se muestra la probabilidad de elección para distintos valores de \(\theta\), \(\sigma\) y \(d\).
Código
import numpy as npimport scipy.stats as statsfrom plotly.subplots import make_subplotsimport plotly.graph_objects as gothetas = [0.1, 0.5, 1, 2]sigmas = [0.1, 0.5, 1, 2]d = np.linspace(-5, 5, 1000)# Definir colores fijos para cada thetacolors = ["blue", "red", "green", "purple"]# Calcular los valores de la función logísticay = [[stats.logistic.cdf(2* d / sigma * theta, loc=0, scale=1) for theta in thetas] for sigma in sigmas]# Crear subplotsfigs = make_subplots(rows=2, cols=2, subplot_titles=[f"σ = {sigma}"for sigma in sigmas])# Agregar trazas con hover funcionalfor j, sigma inenumerate(sigmas): row, col =divmod(j, 2) # Posición en la cuadrícula (0-based) row +=1 col +=1for i, theta inenumerate(thetas): figs.add_trace( go.Scatter( x=d, y=y[j][i], mode="lines", name=f"θ = {theta}"if j ==0elseNone, # Solo mostrar la leyenda en el primer subplot line=dict(color=colors[i]), showlegend=(j ==0), # Mostrar leyenda solo en la primera iteración hovertemplate="<b>d:</b> %{x:.2f}<br><b>Pr(A, B):</b> %{y:.4f}<br><b>θ:</b> "+str(theta) +"<br><b>σ:</b> "+str(sigma) ), row=row, col=col )# Modificar etiquetas de los ejes por subplotfor j, sigma inenumerate(sigmas): row, col =divmod(j, 2) row +=1 col +=1 figs.update_xaxes(title_text=f"d", row=row, col=col) figs.update_yaxes(title_text=f"Pr(A, B)", row=row, col=col)# Configurar diseño general con hover mejoradofigs.update_layout( legend_title="θ", hovermode="x unified")figs.show()
El tiempo necesario para tomar una decisión es aleatorio, dado que depende de la acumulación de evidencia y el ruido en el proceso. En su artículo Busemeyer y Townsend (1993) mencionan que el tiempo esperado o promedio para tomar una decisión se puede calcular como:
Indicando que depende de la diferencia entre las valencias y el umbral de decisión. A mayor diferencia entre las valencias menor tiempo se necesita para tomar una decisión y a un umbral de decisión más grande mayor tiempo se necesita. Esto se conoce como un trade-off entre la velocidad y la precisión o entre costo y beneficio en la toma de decisiones, que en este modelo se puede ajustar con el umbral de decisión \(\theta\). Si una elección conlleva un costo bajo en equivocarse se puede ajustar el umbral a un valor bajo para tomar decisiones rápidas, mientras que si el costo de equivocarse es alto se puede ajustar el umbral a un valor alto para tomar decisiones más precisas.
El siguiente paso en mostrado en la figura Figura 1 es lo que llaman Random Walk SEU que es justo lo que se muestra en el gif (véase figura Figura 2) donde se acumula evidencia a favor de una opción y se decide cuando se supera un umbral, pero se generaliza el punto de partida, ya que en el gif se parte del cero, pero podemos iniciar en cualquier punto. Si el punto de inicio es cercano al umbral de decisión de alguna de las opciones se dice que hay un sesgo en la elección. Este sesgo puede ser provocado por distintos factores como la preferencia por una opción, la cantidad de información que se tiene de una opción, entre otros.
Memoria
Con las modificaciones creadas hasta ahora el modelo es capaz de representar el proceso de deliberación en la toma de decisiones bastante bien y es una plantilla ampliamente recreada en otros modelos similares. Lo que verdaderamente hace único al modelo de Busemeyer es la inclusión de la memoria en el proceso de toma de decisiones. La memoria se incluye para modelar la inconsistencia en las preferencias y el efecto del tiempo en la elección. Para lograrlo se añade un parámetro llamado tasa de crecimiento/decaimiento (\(s\)) que modela la aparición de efectos de recencia y primacía en la elección.
La recencia se refiere a que la información más reciente tiene mayor peso en la elección, mientras que la primacía se refiere a que la información que se presenta primero tiene mayor peso en la elección. La tasa de crecimiento/decaimiento modela la rapidez con la que se olvida la información, si \(0 < s < 1\) se presenta recencia, si \(s < 0\) se presenta primacía y si \(s = 0\) no hay efecto de memoria. Esto es posible dada la forma matemática en la que se añade la memoria al modelo.
En los siguientes gifs se muestra el efecto de la memoria en la elección para un \(s = 0.99\) (Figura 3) y \(s = -3\) (Figura 4).
Figura 3: Efecto de Recencia.
Figura 4: Efecto de Primacia.
El efecto es apenas perceptible, pero se nota que principalmente se ve en el tiempo para decidir. En el caso de recencia se toma menos tiempo, mientras que en el caso de primacía se toma más tiempo.
Control aversivo y apetitivo: Decision Field Theory.
La última modificación al modelo seda al incluir un parámetro \(c\) llamado gradiente objetivo, dado que nos permite dar cuenta de que tan apetitiva son las opciones. Para valores de \(c > 0\) se dice que las opciones son apetitivas, mientras que para valores de \(c < 0\) se dice que las opciones son aversivas. Este parámetro se añade al proceso de acumulación de evidencia de la siguiente forma:
Esta última ecuación representa el modelo completo de Busemeyer y Townsend (1993).
Versión Interactiva.
En el siguiente enlace a Google Colab se puede interactuar con el modelo de Busemeyer y Townsend (1993) para ver el efecto de los parámetros en la elección y el tiempo de decisión.