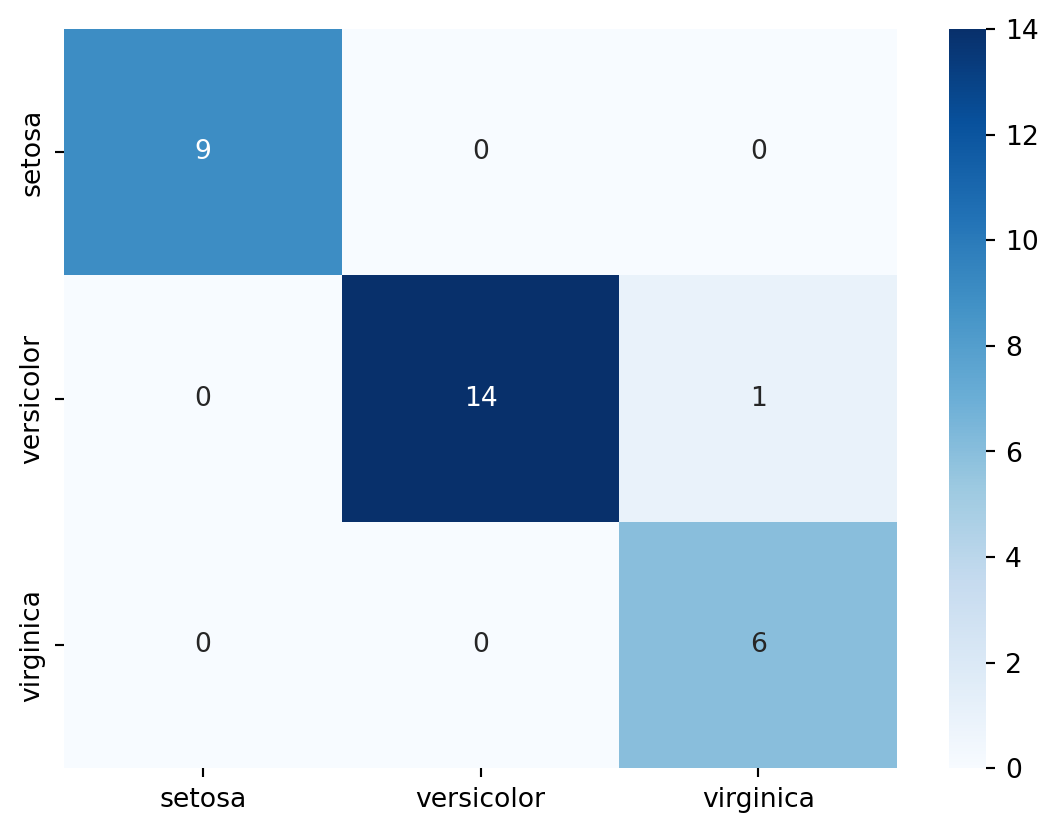
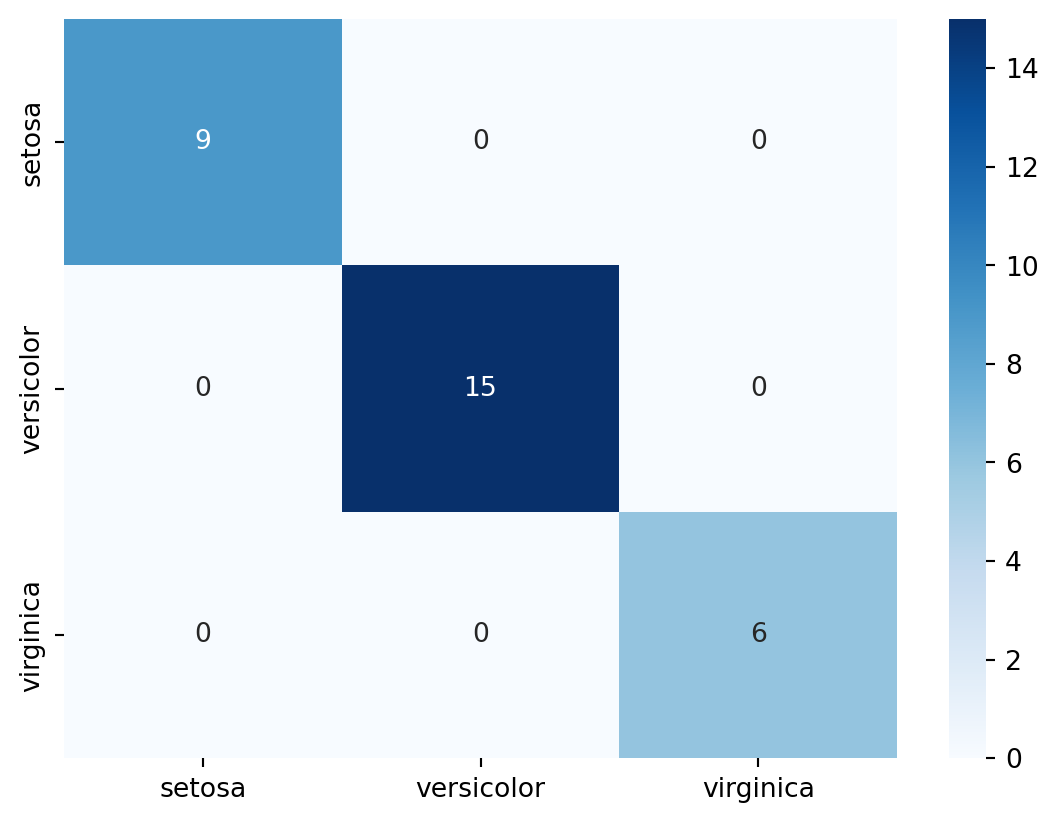
torch.Size([150, 4])
torch.Size([150])
tensor([[0.3815, 0.2707, 0.3478],
[0.3707, 0.2763, 0.3529],
[0.3767, 0.2748, 0.3485],
[0.3761, 0.2767, 0.3472],
[0.3848, 0.2700, 0.3452],
[0.3857, 0.2675, 0.3468],
[0.3805, 0.2740, 0.3455],
[0.3804, 0.2723, 0.3473],
[0.3722, 0.2792, 0.3486],
[0.3762, 0.2751, 0.3487],
[0.3846, 0.2679, 0.3474],
[0.3825, 0.2732, 0.3442],
[0.3740, 0.2762, 0.3498],
[0.3763, 0.2772, 0.3465],
[0.3872, 0.2628, 0.3499],
[0.3947, 0.2610, 0.3442],
[0.3835, 0.2665, 0.3500],
[0.3790, 0.2712, 0.3498],
[0.3833, 0.2669, 0.3498],
[0.3871, 0.2685, 0.3445],
[0.3782, 0.2714, 0.3503],
[0.3820, 0.2700, 0.3479],
[0.3859, 0.2704, 0.3438],
[0.3707, 0.2750, 0.3542],
[0.3841, 0.2740, 0.3418],
[0.3710, 0.2765, 0.3525],
[0.3759, 0.2736, 0.3505],
[0.3813, 0.2706, 0.3481],
[0.3782, 0.2713, 0.3505],
[0.3783, 0.2756, 0.3461],
[0.3751, 0.2763, 0.3487],
[0.3722, 0.2719, 0.3559],
[0.3988, 0.2640, 0.3371],
[0.3958, 0.2623, 0.3418],
[0.3737, 0.2756, 0.3506],
[0.3738, 0.2735, 0.3527],
[0.3777, 0.2690, 0.3532],
[0.3881, 0.2698, 0.3420],
[0.3741, 0.2779, 0.3480],
[0.3796, 0.2719, 0.3485],
[0.3793, 0.2713, 0.3494],
[0.3538, 0.2849, 0.3613],
[0.3791, 0.2759, 0.3450],
[0.3735, 0.2737, 0.3529],
[0.3867, 0.2701, 0.3432],
[0.3691, 0.2772, 0.3537],
[0.3901, 0.2682, 0.3417],
[0.3781, 0.2754, 0.3465],
[0.3854, 0.2683, 0.3463],
[0.3773, 0.2730, 0.3496],
[0.3250, 0.2925, 0.3825],
[0.3263, 0.2936, 0.3801],
[0.3203, 0.2957, 0.3840],
[0.3146, 0.3016, 0.3837],
[0.3154, 0.3000, 0.3847],
[0.3272, 0.2929, 0.3800],
[0.3270, 0.2936, 0.3794],
[0.3322, 0.2924, 0.3754],
[0.3230, 0.2938, 0.3832],
[0.3244, 0.2970, 0.3785],
[0.3196, 0.2988, 0.3816],
[0.3244, 0.2961, 0.3795],
[0.3173, 0.2974, 0.3853],
[0.3239, 0.2944, 0.3816],
[0.3294, 0.2935, 0.3772],
[0.3242, 0.2940, 0.3818],
[0.3271, 0.2943, 0.3786],
[0.3342, 0.2883, 0.3776],
[0.3119, 0.3071, 0.3809],
[0.3256, 0.2940, 0.3803],
[0.3213, 0.2986, 0.3800],
[0.3233, 0.2955, 0.3811],
[0.3136, 0.3026, 0.3839],
[0.3275, 0.2911, 0.3814],
[0.3241, 0.2940, 0.3818],
[0.3223, 0.2953, 0.3824],
[0.3160, 0.2979, 0.3861],
[0.3157, 0.3008, 0.3834],
[0.3213, 0.2972, 0.3815],
[0.3307, 0.2913, 0.3780],
[0.3234, 0.2956, 0.3810],
[0.3272, 0.2933, 0.3795],
[0.3259, 0.2940, 0.3801],
[0.3147, 0.3010, 0.3843],
[0.3287, 0.2937, 0.3776],
[0.3317, 0.2916, 0.3767],
[0.3216, 0.2956, 0.3828],
[0.3131, 0.3023, 0.3846],
[0.3331, 0.2904, 0.3765],
[0.3200, 0.2984, 0.3816],
[0.3268, 0.2932, 0.3801],
[0.3265, 0.2931, 0.3804],
[0.3234, 0.2953, 0.3813],
[0.3282, 0.2944, 0.3774],
[0.3248, 0.2950, 0.3802],
[0.3364, 0.2879, 0.3757],
[0.3294, 0.2921, 0.3784],
[0.3257, 0.2934, 0.3809],
[0.3285, 0.2949, 0.3766],
[0.3266, 0.2940, 0.3794],
[0.3149, 0.3109, 0.3742],
[0.3139, 0.3066, 0.3794],
[0.3139, 0.3074, 0.3787],
[0.3150, 0.3018, 0.3833],
[0.3141, 0.3085, 0.3774],
[0.3133, 0.3066, 0.3801],
[0.3142, 0.3049, 0.3809],
[0.3139, 0.3020, 0.3841],
[0.3121, 0.3071, 0.3808],
[0.3163, 0.3076, 0.3762],
[0.3162, 0.3037, 0.3801],
[0.3134, 0.3073, 0.3793],
[0.3143, 0.3078, 0.3779],
[0.3125, 0.3112, 0.3763],
[0.3129, 0.3155, 0.3716],
[0.3153, 0.3091, 0.3757],
[0.3154, 0.3012, 0.3834],
[0.3179, 0.2985, 0.3836],
[0.3100, 0.3151, 0.3749],
[0.3120, 0.3055, 0.3826],
[0.3147, 0.3090, 0.3762],
[0.3145, 0.3075, 0.3780],
[0.3123, 0.3070, 0.3807],
[0.3139, 0.3061, 0.3800],
[0.3162, 0.3033, 0.3805],
[0.3160, 0.2988, 0.3852],
[0.3146, 0.3049, 0.3805],
[0.3159, 0.3019, 0.3821],
[0.3133, 0.3093, 0.3774],
[0.3154, 0.2978, 0.3868],
[0.3130, 0.3059, 0.3811],
[0.3184, 0.2957, 0.3859],
[0.3130, 0.3113, 0.3757],
[0.3172, 0.2980, 0.3848],
[0.3172, 0.2967, 0.3861],
[0.3127, 0.3121, 0.3752],
[0.3162, 0.3076, 0.3762],
[0.3161, 0.2998, 0.3841],
[0.3160, 0.3020, 0.3820],
[0.3148, 0.3070, 0.3782],
[0.3140, 0.3122, 0.3739],
[0.3143, 0.3118, 0.3739],
[0.3139, 0.3066, 0.3794],
[0.3148, 0.3083, 0.3769],
[0.3149, 0.3114, 0.3737],
[0.3138, 0.3124, 0.3738],
[0.3123, 0.3104, 0.3773],
[0.3149, 0.3060, 0.3791],
[0.3167, 0.3059, 0.3775],
[0.3164, 0.3010, 0.3826]], grad_fn=<SoftmaxBackward0>)